Published:
5 min read

Explore Statusphere: The open-source, API-first status page aggregator. Centralize service statuses. Contribute on GitHub!
Today, we open-sourced Statusphere: an api-first status page aggregator. Statusphere is a 1-stop location for machine readable service status. Check it out, we're actively looking for and accepting contributions!
We built Statusphere to solve 4 problems with external system status:
Machine readability
Discoverability
Centralisation
Standardisation
If you know these pains well then skip this section, otherwise read on.
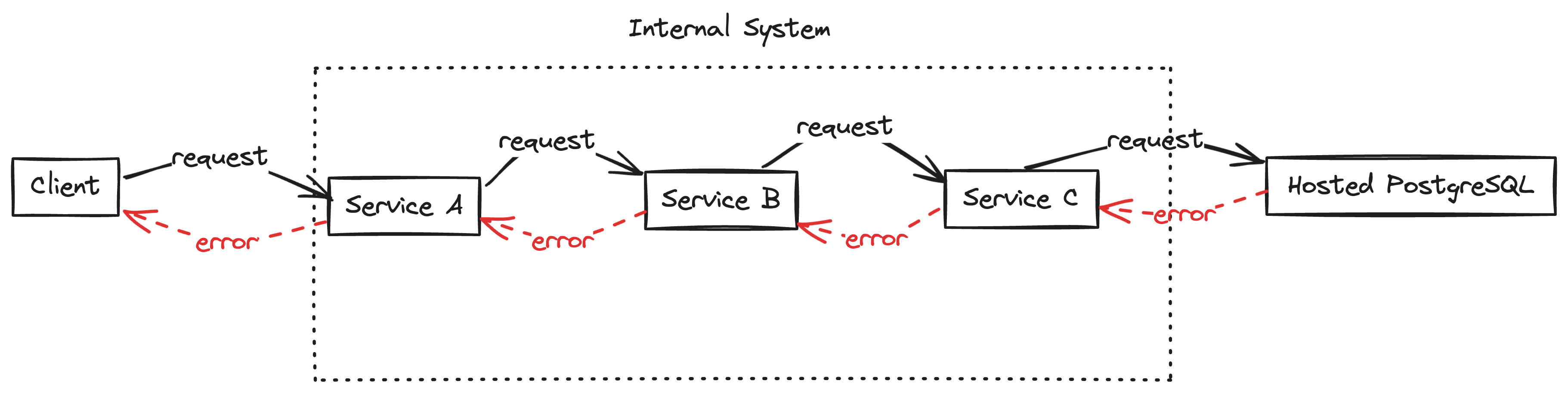
In this scenario we have an internal micro-service system comprised of A, B and C which all call each other in succession after a client makes a request to service A. Finally C calls out to a hosted Postgres instance that we don't manage internally. In this scenario our client is seeing errors and we want to figure out why.
When we're debugging these internal systems using distributed traces it's often fairly easy to know that service C is the root cause of our issues in service A by just following the trace and seeing that the each request to the next service returned an error.
However, when we cross the internal system boundary to a service we don't own like our hosted PostgreSQL instance, things can get a little more complicated.
Here, we don't have any trace information so we might have to dive into the logs to see that we're getting an error back from the database. Even then it can be unclear why we're seeing an error if it's something opaque like a timeout. Did we change our query pattern? Did we hit some constraint on the capacity of the database? Or is the database actually down?
At this point, you might google something like EXTERNAL POSTGRES HOSTING COMPANY status page , you may or may not find something. These status pages are often poorly indexed by google if your provider is even slightly obscure. Even some of the large providers can't be found easily. Try searching redis status page, let me know if you can find https://status.redis.com/ , the official status page. I couldn't see it on the first 3 pages of google. This is the discoverability issue.
If you do find something then you'll probably see something like Issue known, investigating . Great, now everyone can relax, once the provider is back up and running, things should be back to normal for us too. However, that would have been great to know before we started debugging, paged people in etc.
Well maybe that is possible, if we could check all our dependencies programmatically when we start an investigation and see immediately that our database provider is having issues, we could have avoided a lot of this pain, maybe we could even avoid paging anyone at all... This is why machine readability is important. However, status pages today are not readily accessible by api.
Even if you could hit an api to get the status, each status page vendor wouldn't have the same api and maintenance would be a mess. This is why we need centralisation and standardisation. Statusphere deals with all the different providers so that you don't have to.
Why do we care enough to build this? At Metoro, we're trying to automate the process of debugging production issues. Understanding that an external dependency is degraded allows us to provide more accurate automated root causes for our customers. If you're mapping the broader workflow around triage, remediation, communications, and postmortems, our AI incident response tools guide covers where dependency context fits into the stack.
Statusphere is an open source Go / Typescript project that you're free to stand up yourself, or alternatively you can use the instance we host at https://www.statusphere.tech/.
# Give it a go
curl 'https://statusphere.metoro.io/api/v1/statusPages' | jq
There's also a frontend you can use at https://statusphere.tech.
Conceptually Statusphere is pretty simple. It takes a list of status pages, periodically scrapes the incident history and current status from them and updates a database with the results. This can then be queried through an api.
Statusphere is made up of 3 main components:
The scrapers
The database
The api servers
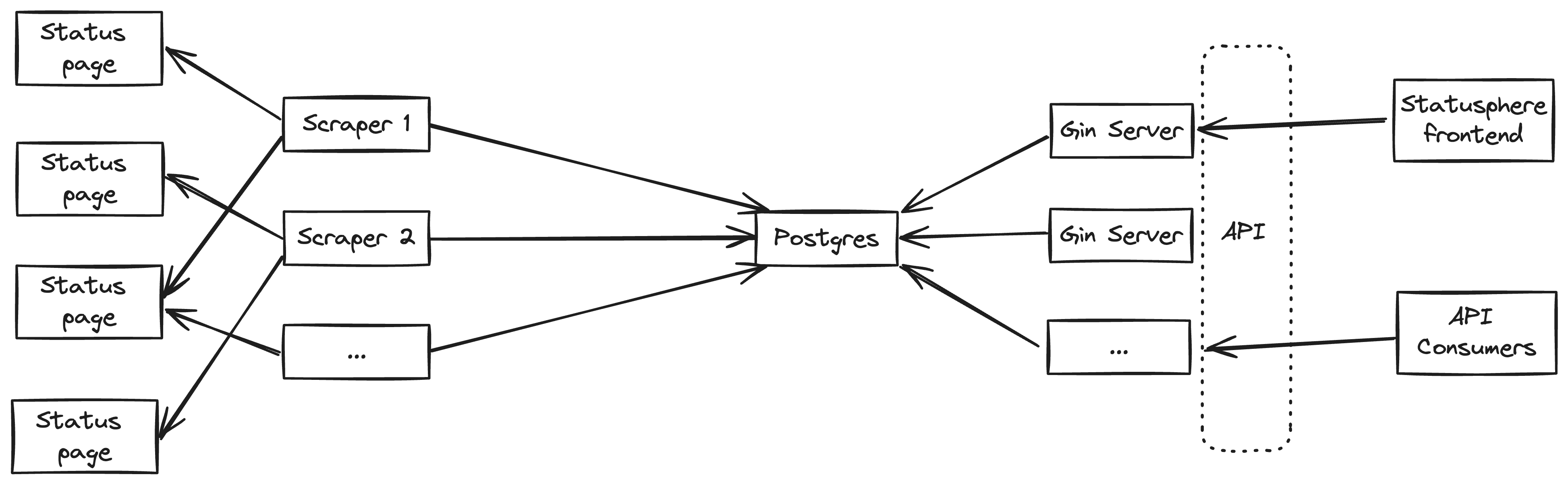
Each scraper comes online, pulls the list of pages to scrape from the database and when they were last scraped. Every second they check to see if they should start a scrape for any of the status pages. If they do then they spawn a new goroutine to which will scrape the page and push the findings to the database.
Scraping is done in a cascading fashion through providers. Each provider is capable of scraping a specific type of status page. For example: the status.io provider is capable of scraping all of the pages created through status.io's platform. If a provider is incapable of scraping a particular page then it fails and the next provider is tried. This allows status pages to be added to Statusphere which it is not yet currently capable of scraping. In this case all providers fail to scrape the page and Statusphere simply acts as a directory specifying that you should go to the statuspage yourself to get current / past incidents.
If a page is successfully scraped, then it is marked as indexed and the details of all past / current incidents are exposed over the api.
The api servers are simple gin servers serving the following endpoints:
GET /api/v1/statusPage?statusPageUrl=XXX||statusPageName=XXX
GET /api/v1/currentStatus?statusPageUrl=XXX
GET /api/v1/statusPages
GET /api/v1/statusPages/count
GET /api/v1/statusPages/search?query=XXX
GET /api/v1/incidents?statusPageUrl=XXX
All of the endpoints are publicly accessible by default. Feel free to try them out. The baseUrl of the public server is https://www.statusphere.tech.
curl 'https://statusphere.metoro.io/api/v1/incidents?statusPageUrl=https://www.githubstatus.com' | jq
The public frontend is at https://statusphere.tech and the github is at https://github.com/metoro-io/statusphere
And that's all, let us know what you think!

More Metoro articles that deepen the same topic from another angle.
Know enough to be dangerous in 10 minutes
Read article →Compare 9 AI incident response tools for SREs and DevOps teams, with tradeoffs across triage, root cause analysis, remediation, and communications.
Read article →Detailed answers to common questions about microservices, starting from the basics and getting into the details
Read article →